Stitch/Strata
This is the first piece in the portfolio of works for this PhD. The recording that is submitted is a stereo version that attempts to capture the spatialisation from the first performance at the 2019 Electric Spring Festival using the Huddersfield Immersive Sounds System (HISS).
Motivations and Influences
At the beginning of this PhD, I focused on the question: How can the computer be creative in my compositional practice?. This question reflected the curiosities catalysed by a previous project, Biomimicry, in which the computer was programmed to respond to an improvising instrumental performer and appeared to act creatively in the way that it managed musical form in real-time. Improvisations with Biomimicry gave rise to musical structures that I did not specifically plan or encode into the system, and produced sophisticated micro-, meso- and macro-scale formal trajectories. Furthermore, the transitions between different real-time generated musical states and behaviours felt natural and almost intentional. That said, I do not think that these aspects and qualities were necessarily attributable to the computer alone nor my programming prowess. In my view, it was mostly the improviser’s ability to shape the flow of the improvisation that gave rise to such complex and musically satisfying results. Because the computer only responded to what the performer did, the improviser drove formal events and the computer reacted to the changes and structuring of time imposed by the human counterpart. Reflecting on this, my supervisor Dr. Alex Harker encouraged me to write a piece, subsequently called Stitch/Strata, without any improvisers or instrumentalists to help structure a live electronics work through interaction. The aim of this challenge was to remove the in-the-moment influence of an intelligent and musically capable human, thus encouraging me to find computational strategies for creating sophisticated formal structures through generative and computer-originated processes.
Given this context, a major motivation for this project was to investigate how the computer could structure all formal levels of a work, from the selection of individual compositional units (in this case audio samples), their arrangement into gestures, their arrangement into sequences of gestures and so on, until the work is additively built from a set of atomic units by a governing algorithm. A goal of this compositional workflow would be to take my influence away from arranging materials at different levels of detail, to inventing procedures that the computer would then use to realise a work automatically and to achieve a sense of coherence and sophistication in the output. In this regard, a number of other practitioners influenced me and drove this type of thinking.
Other Practices
Michael Young’s Neural Network Music (NN Music) system was particularly prominent in my set of influences. In NN Music, the computer acts as an improvisational partner that can move between a number of states to accompany and make music with an instrumental performer. It decides which state to occupy by performing real-time classification of the instrumentalist’s playing, and associating this detected state to one of several internal states. The caveat of Young’s approach in this piece, is that the computer begins with a limited understanding of how to do this, which is then built up throughout the piece using a neural network. This network is constantly retraining on-the-fly and forming a bond between a set of behaviours and musical constructs it has stored in memory and the performance in the moment, rather than their being pre-composed.
While Young’s piece relies on collaboration and the musical sensitivity of the improviser, I found the technological approach of this work inspiring for two reasons. Firstly, much of the composing is done without necessarily making decisions about specific and detailed musical structures. Instead, Young creates a generalised model for what he deems to be important musically, and this model is open-ended and flexible to an extent. Secondly, the computer seemingly forms its own connections between the content of the improvisers musical behaviour and its response. Those connections are not explicitly pre-composed or made ahead of time and instead are formed dynamically in the moment, allowing the inherent properties of the neural network to be infused into the character of the piece and the structural unfolding of the improvisation in time.
At the time of composing Stitch/Strata I was also reading articles by Adam Linson and became interested in his improvisational and creative coding practice. In particular, I found the way that he incorporates the computer into his musical practice as an autonomous creative agent something that I could learn from and adapt to my own needs. Linson et al. (2015), for example, describes the design of Odessa, a real-time improvisation system that uses a “subsumption architecture” to construct its behaviour. The architecture is described as follows:
In Subsumption terminology, the “competing behaviors” of a system are organized into a network of interactive “layers” (Brooks 1999). Following this idea, and further informed by psychological research, Odessa’s behavioral layers consist of its basic agency to spontaneously produce output (“Play”), its ability to respond to musical input (“Adapt”), and its ability to resist by disregarding musical input, introducing silence, and initiating endings (“Diverge”). (Linson et al., 2015, p. 4)
IMAGE 4.1.1 depicts how the architecture of Odessa is designed as a set of behavioural layers that contain modules for sound production and interaction. These are sensitive to the input of a live performer. By connecting these modules to each other across the subsumption architecture, Linson et al. (2015) hypothesised that it “would serve to produce cues that suggest intentionality” (p. 13). For me, the notion of intentionality was also something that I wanted to be able to build into my work. What I often interpret as “sophistication” in computational and computer generated outputs is a sense that the computer’s musical decision making is intentional. The rationale for these decisions does not necessarily have to be concrete or explainable, but it has to seem as if there is something guiding the decision-making process in a similar fashion to the way I might manually compose.
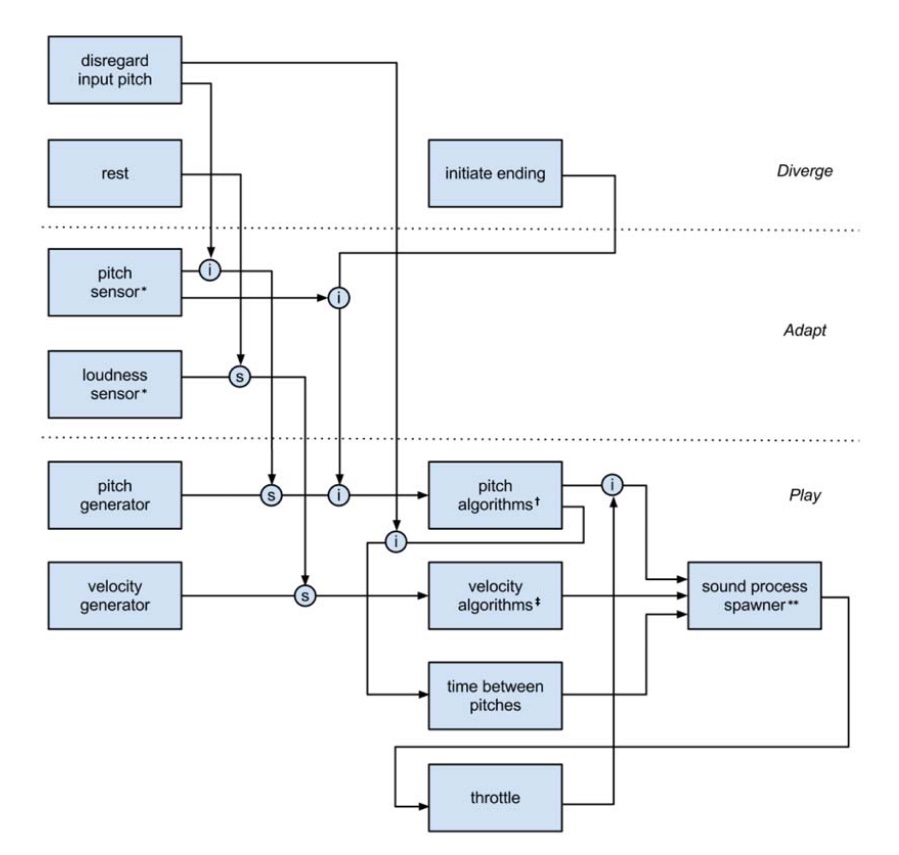
IMAGE 4.1.1: Odessa subsumption architecture taken from Linson et al., (2015). The boxes represent modules belonging to one of the three behavioural layers, "Play", "Diverge", "Adapt".
The subsumption architecture was also interesting to me as a potential method for approaching the problem of having the computer deal with time and form on multiple levels. I envisaged that with this architecture, or something similar, I could construct different formal levels as layers and then devise various mechanisms for how those layers would interact with each other. Similar to my appreciation for Young’s work, the computer would not have to be specifically programmed to deal with the minutiae of musical decision-making; rather, I could build a system that embodied a number of strategies for dealing with decision-making, and the musical details would resolve themselves computationally.
While these influences and potential strategies in the early stages of research and conceptual exploration felt promising, the generalisations I made about the application of technology led to many failed attempts to compose a piece with the initial goals in mind. This created a frustrating compositional process, so much so that by the end of composing Stitch/Strata I had moved far away from the initial territory I had aimed to explore by working “in the computer”. In doing so, relied on manual intuitive compositional decision making to finish the piece in a hybrid computer-aided workflow situated in the Digital Audio Workstation (DAW). The evolution to this end-point and the compositional process is described next in [4.2 Compositional Process].
Compositional Process
In this section I will describe the compositional process of Stitch/Strata from the earliest experiments to the final result. Along the way I will detail some additional musical influences and reflect on the trajectory of this particular piece and project. To do this I will draw on code written in Max and Python as well as sounds which were produced from experimentation and trial and error. However, this should be caveated by the fact that during the compositional process, I would not always be sure if patch or script would be used or significant in the development of the piece. Because of this, some of the code was left unfinished while I was experimenting with it and reached a dead end. Furthermore, the coding style I used when composing this piece is in some ways not reflected in the coding style that I have developed now. This made it difficult to reverse engineer my compositional decision making in some scenarios or to identify how specific sections of the code contributed to the overall work. From my perspective now, I have attempted to extract the most salient technological items and sound outputs to explain the development of the piece.
The Influence of Experimental Vocal Improvisation
Most, if not all, artistic projects for me are initiated by my responding to sonic materials. This might be a surface-level appreciation of a specific group of sounds, or perhaps a material type that sparks compositional imagination which I have gathered and collected. Alongside the compositional influences described in [4.1.1 Motivations and Influences], listening had a significant impact on this project and catalysed a process of collecting sounds with which to compose. In this aspect of the piece, Sage Pbbbt’s catalogue of vocal improvisation daily sketches served as a trove of sonic materials that I would later draw on and use as audio samples. These improvisations initially compelled me by their deep exploration of extended techniques and the diverse morphologies and textures that could be produced by the voice alone. In connection with Pbbbt’s practice, I came into contact with the discography of Phil Minton as well as his collaborative efforts with Audrey Chen in By The Stream (2013) .
One particular aspect of By The Stream that was evocative for me, was the way that I interpreted the construction of long form textures as assemblages of intricate vocal utterances. To me, the arrangement of individual sounds in this way transformed them from their organic method of production into something synthetic and abstract. This can be heard in as from 0:56 to 1:35, where rapid and inhalations form a noise-based textural stream, and 2:38 to 3:10 in all, where short utterances and phonemes are strung together into a gestural almost rhythmic pattern.
AUDIO 1: By The Stream (2013) – Phil Minton and Audrey Chen
In addition to this work, I came across Trevor Wishart’s Tongues of Fire (1994). This piece uses vocal sounds as a source material and introduces signal processing in order to manipulate sounds into new forms. I took particular interest in the way that the Wishart occupied the sonic territory between organic and synthetic presentations of the source material, facilitated by rapid concatenation and processing. 13:06 to 15:24 in particular emphasises this in VIDEO 4.1.1.
VIDEO 4.1.1: Tongues of Fire (1994) — Trevor Wishart
At this point of development in my practice, extended vocal techniques were a material that I wanted to work with in this project more deeply. I myself am not a vocal improviser and needed some source materials to compose with and decided to use the entirety of the daily sketches by Pbbbt as a starting point due to the liberal Creative Commons license. Many of the individual sounds that I found appealing from other practices were made available as a part of this corpus, because there is such an extensive body of material, techniques and approaches by Pbbbt. My plans from this point were to deconstruct the corpus through segmentation, and have the computer use those segments as its compositional material to operate on generatively and algorithmically.
Building a Corpus of Materials
I began by segmenting all of the recordings using REAPER’s dynamic split tool and configuring it to segment based on the detection of transients. I selected this strategy because I wanted to extract individual utterances and phoneme sounds to be rearranged and concatenated by the computer. DEMO 4.1.1 shows an example of this process, in which I took a portion of One Breath Poem Failure, segmented it and then recombined those segments randomly. The colours of each segment track the change in arrangement of each utterance between the segmentation and reordering stages.
This was only a single experiment, and applying it to other source material revealed to me a number of compositional possibilities which could be achieved through this deconstructive process. Depending on the qualities and nature of the source, individual segments could synthesise new forms and sounds with their own novel character and synthetic qualities. Thus, this spawned the next level of compositional development in this project, and I imagined that a whole piece could be made by creating a system that would be responsible for organising samples in this way into phrases and organising those phrases into a whole piece. I did not have a strong idea about what would specifically constitute a phrase at this time, but I knew that I wanted to explore recombining segments such that the result would be less random than the initial experiments, and that phrases could be given strong perceptual qualities that would differentiate them from each other. With this idea in mind, I set out to experiment with a number of approaches in which individual segments would be concatenated into phrases.
I began by using audio descriptors to analyse the amplitude, spectral centroid and spectral flatness measure of each sample. I anticipated that for a generative strategy predicated on selecting samples according to their perceptual attributes, these three categories of data would allow the computer to differentiate sounds from each other by capturing their “brightness” (spectral centroid), “noisiness” (spectral flatness) and intensity (amplitude). I could then prompt the computer to find samples that were relatively homogenous with each other and to draw them together into phrases or compositional units. Using a Max patch, I was able to test this idea by querying a database of this descriptor information to return samples that fit a set of criteria and then concatenate them randomly within that group of samples. In VIDEO 4.1.2 I demonstrate this by querying for up to 50 samples from the corpus of segments based on three different constraints. Each slider corresponds to a different descriptor query, so by changing the value in this interface I can modify it in real-time. The comparison operations of this descriptor query are fixed. They are as follows:
- Samples that have a spectral centroid greater than the threshold
- Samples that have a spectral flatness measure greater than the threshold
- Samples that have an amplitude within 6dB of the threshold
Using the computer to query the corpus and find groups of samples matching a particular descriptor specification produced results that appealed to me aesthetically. In particular, queries that produced texturally focused groupings were the most appealing, especially when subjected to the process of concatenating them in rapid succession. This produced static textures with intricate and detailed morphologies without my having to make specific decisions regarding the duration or timing of individual samples. I also discovered that this technique was potent for shaping and controlling the morphology imposed on to the concatenation process by changing the thresholds of the query dynamically. This can be seen specifically at 0:20 in VIDEO 4.1.2.
This descriptor-query process underpinned much of the compositional process to follow. From this point, I attempted to devise ways in which the computer could arrange material at a higher formal level by imposing ordering and patterns on to groups of samples and by modifying descriptor queries dynamically. This is discussed in the next section, [4.1.2.3 Attempts to Have the Computer Generate Form].
Attempts to Have the Computer Generate Form
Referring to some of my initial goals for this piece, I wanted the computer to be able to construct multiple formal levels of the work by operating hierarchically. Prior to working with the vocal materials I imagined a computer system that would incrementally arrange samples into gestures, gestures into phrases and those phrases into sections. While experimenting with the audio descriptor matching described in [4.1.2.2 Building a Corpus of Materials], I anticipated that by leveraging audio descriptors further, I could have the computer organise samples according to the percept across these levels. Up to this point in the composition process, I had mostly been creating short concatenations of sounds based on their descriptor attributes, and had not been considering these outputs within the context of a longer piece. As such, the experimentation that followed was mostly concerned with how I could imbue the computer with the next level of formal decision making.
One approach was to create predefined query “shapes” that structured a dynamic query over a given period of time. Using this, I could define the overall quality and percept of the gesture, without specifying any of the particular curatorial and selective details, such as which samples would form that gesture. A similar approach is discussed in Harker (2012), in which he outlines how bespoke Max externals have been used toward similar ends in his compositional practice. VIDEO 4.1.3 demonstrates one implementation of this, where queries are changed according to a gesture that is defined by a number of points to be reached at specific times. This creates a parabolic trajectory that increases and decreases the amplitude and spectral centroid query values over a set amount of time. This produces a strong perceptual link between the query and the sound which as a compositional tool is a useful way of having the computer render complex morphologies through a set of constraints.
VIDEO 4.1.4 shows another strategy in which a static state of very low amplitude is intermittently “escaped” from, by updating the query for new samples in real-time and almost immediately returning to the low amplitude state. This creates a series of jumps between static states.
Another approach involved designing a behaviour on the metaphor of “adversarial searching”. For this, I took two starting points within the descriptor space and attached those starting points to two simultaneous searches, one that attempts to minimise the volume of the output by changing the spectral centroid and one that tries to find the maximum centroid by minimising the volume. These two searches subsequent turns in determining the selected sample, forming a single perceivable stream of concatenated segments. This adversarial process has no end, but produces longer term morphologies and structures without having specifically to design them from moment-to-moment. This kind of thinking carried over, and was a precursor in many ways, to my engagement with simulated annealing in Annealing Strategies, which exploits a similar searching behaviour to structure music automatically. The adversarial searching technique produced sophisticated meso-scale forms, in which seemingly intentional structures emerged. However, it mostly generated dull and meandering macro-scale structures. AUDIO 4.1.2 presents an output of this process.
The final strategy I tried was to take the outputs from descriptor queries and apply a more rigorous, statistical selection procedure. This selection procedure was an implementation of the z12 algorithm described in Puckette (2015) which can generate different patterns by specifying probabilities between different outcomes. DEMO 4.1.2 shows an example of the patterns this process can generate.
I imagined that imposing this type of rigorous statistical process over an already perceptually linked group of samples would result in structures that might be formally sophisticated. This was not the case, however, because the algorithm’s behaviour was too homogenous in the sense that it always changed. While I imagined that the z12 algorithm might impose some level of structure over concatenations the end result was in my perception no different than just randomly shuffling the samples.
The purpose of exploring these approaches was to enable the computer to generate high-level formal structures from a computational and descriptor-driven approach to selecting different sample-based materials over time. Overall though, these strategies did not produce sophisticated high-level forms, something that I was concerned with from the outset of the project. While certain aspects of these strategies produced some aesthetically appealing outputs, this workflow was mostly uninspiring, and my interactions were entirely grounded in the design of algorithmic procedures or tweaking parameters of queries. Furthermore, this way of approaching the automatic generation of formal structures was framed around recreating those structures which I would find sophisticated, rather than trying to have something emerge from creating a set of algorithmic or generative constraints. In hindsight, I do not think that the algorithms and models I was using were sufficiently complex, nor did I have a sufficiently sophisticated idea about what aspects of my formal thinking could or should be modelled at the meso- and macro- levels of form.
Fundamentally, the way I was working at this time introduced an increasing number of compositional decisions into the creative process, without addressing my initial aims of having the computer generate a piece at all formal levels. I found more interest in being offered small sections of material and I often wanted to go away and compose with these ideas, but I stopped myself in order to go back and explore other strategies, which I thought in combination would eventually lead to a system that could produce a piece by itself. Ultimately, the frustration of not progressing towards a finalised piece-, prompted a radical change in approach to how I composed from that point onwards.
From Modelling to Assistance
At this point in the project I engaged in a radical shift of technology and approach. One aspect that I wanted to continue was descriptor-based querying to create small collections of material. What I wanted to change was the role of the computer in organising the outputs of those processes: to rely more sparingly on algorithmic and generative approaches and to explore their arrangement into high-level forms through intuition. Despite initially having a strong desire to compose “in the computer”, I realised that was incompatible with my need to be involved in the creative process more directly.
A significant change that also emerged at this point was to my creative-coding environments. I began by recreating ideas previously made in Max in Python, and testing how I could implement and express procedures such as audio descriptor matching and concatenative synthesis. There were a number of reasons for this, but the shift was mainly a response to the lack of development in, as well as the unmanageability of, the technical work I had already done. In the initial experiments for this project I had created numerous Max patches, some in a functional state and others broken or abandoned. This state of disrepair in the programming aspect of the project made it hard to iterate on existing work, or to synthesise different approaches into hybridised new ones. I felt that I needed a fresh start where I could be as expressive as possible without considering the “technical debt” of what I had created before. Furthermore, as I experimented more and more I became increasingly aware of an underlying incompatibility in how I wanted to express and interact with the outputs of the computer. Much of what I was doing revolved around producing iterations or variations of processes and auditioning them. For me, Max is not an environment that is well suited to such procedures, particularly if one is interested in off-line processing in order to produce many iterations rapidly. It lacks programming constructs such as the commonly found “for” loop, a control flow statement common to many text-based languages which allow one to execute a repeated procedure or function a number of times often in response to some other data. As such, I often found resistance from Max to the conversion of my ideas into a computational form.
By using Python, the compositional process accelerated, and I quickly found good results by combining descriptor query matching to select samples, and pattern-based processes to arrange those matched samples into short musical phrases. This workflow was based around interacting with the command line, a text-based interface where one enters input data that the program interprets in order to modify its function. As such, I would first specify a descriptor query such as amp <-> 3 -16 centroid > 3000 sfm < 0.1 (amplitude within 3db of -16 and centroid greater than 3000Hz and spectral flatness measure less than 0.1) followed by a type of organisational procedure (these are explained shortly in [4.1.2.4.1 Processes for Micro- and Meso-Scale Structures]). These two stages were separate and independent of each other, creating room for experimentation by combining different descriptor queries with a small number of organisational principles. Each time this process was executed, several iterations of the outputs were made, allowing me to audition and aurally explore several variations as a collection. I found this to be a particularly stimulating creative act, because once I had finished Python scripting, I could fully step into the mindset required to listen to materials and imagine their compositional usefulness.
Processes for Micro- and Meso-Scale Structures
Using Python made it possible and easier for me to express a number of organisational procedures that would operate on collections of descriptor-based selections from the wider corpus. I composed these procedures as functions that could be called to create output sound files. Each function has its own logic that drives the basis for selecting samples, thus making each one produce outputs of a certain character. These functions are described next and code has been provided for reference.
def accum_phrase(iterations, joins):
iterations = int(iterations)
joins = int(joins)
sample_set = EntryMatcher()
sample_set.input_vars(input('Enter a descriptor set - Format is [Amp, AmpSpread, CentOp, Centroid, DurOp, Duration]'))
sample_set.match()
sample_set.store_metadata()
concat = AudioSegment.empty()
join_sound = AudioSegment.empty()
if len(sample_set.results) != 0:
for x in range(iterations):
for i in range(joins):
rand = rn.randint(0, len(sample_set.results)- 1)
choice = str(sample_set.results[rand])
join_sound = AudioSegment.from_file(source+choice+affix)
concat = concat.append(join_sound, crossfade=0)
num_iter = str(x) # convert the iteration number to string
concat.export(new_dir+num_iter+affix, format="wav") # export cmd
else:
print("No samples matched")The accum_phrase function (see CODE 4.1.1) concatenates samples until a maximum total duration has been satisfied. The output of the process also renders each stage of the accumulation, so the results can be navigated as a phrase of increasing complexity and duration. This can be heard in AUDIO 4.1.3. While this is perhaps the most simplistic example, it produced results that were largely promising as a first attempt.
def jank(iterations, joins, join_length_min, join_length_max):
#Function Variables#
iterations = int(iterations)
joins = int(joins)
concat = AudioSegment.empty()
join_sound = AudioSegment.empty()
#Generate a list of samples under 500ms and scramble/permute them#
jank_samps = [None] * joins
short_samples = EntryMatcher()
short_samples.input_vars("-96 48 > 0 > 100")
short_samples.match()
for j in range (joins):
jank_samps[j] = rn.choice(short_samples.results)
#NO DESCRIPTORS#
for x in range(iterations):
concat = AudioSegment.empty()
rn.shuffle(jank_samps)
for i in range(joins):
rep = rn.randint(join_length_min, join_length_max)
choice = str(jank_samps[i])
join_sound = AudioSegment.from_file(source+choice+affix) # append the sound to the concatenation stream
concat += join_sound * rep
num_iter = str(x) # convert the iteration number to string
concat.export(new_dir+num_iter+affix, format="wav") # export cmd
short_samples.store_metadata()
print("I am done")The jank function (see CODE 4.1.2) generates phrases where samples are repeated in chunks of a given length as well as applying some variation to that length. The result is a stutter effect that can contain robotic, artificial qualities with tones and pitches as a side-effect. An example of this can be heard in AUDIO 4.1.4 and AUDIO 4.1.5.
def search_small(iterations, joins): # search for small groups with random properties
length_results = 0
small = EntryMatcher()
while length_results < 10 or length_results > 20:
small.results = []
rand_amp = rn.randint(int(amp.min()), int(amp.max()))
rand_spread = rn.randint(3, 18)
rand_cent = rn.randint(int(centroid.min()), int(centroid.max()))
rand_dur = rn.randint(int(duration.min()), int(duration.max()))
small.input_vars(rand_amp, rand_spread, rand_cent, rand_dur)
small.match()
length_results = len(small.results)
print(length_results)
for x in range(iterations):
concat = AudioSegment.empty()
prev_rand = -1
for i in range(joins):
rand = rn.randint(0, len(small.results) - 1)
if prev_rand != rand:
choice = str(small.results[rand])
join_sound = AudioSegment.from_file(source+choice+affix)
concat = concat.append(join_sound, crossfade=0)
prev_rand = rand
rand = rn.randint(0, len(small.results) - 1)
elif prev_rand == rand:
rand = rn.randint(0, len(small.results) - 1)
num_iter = str(x) #convert the iteration number to string
concat.export(new_dir+num_iter+affix, format="wav") # export cmdsearch_small (see CODE 4.1.3 generates a random descriptor query of a narrow range for the amplitude, spectral flatness measure and spectral centroid. This process produces perceptually tight organisations of samples without my having to specify those constraints exactly. I produced many iterations using this and selected those that I found to be the most aesthetically pleasing. Working with this process allowed me blindly to discover descriptor queries that I could then supply to the other functions, generating more avenues for exploration. An example can be heard in AUDIO 4.1.6.
There were several other functions that I developed, highest_centroid, long_short, long_short_exp and meta_construction. I trialled these, but ultimately did not use them. Despite only using the three just described (jank, search_small, accum_phrase), I was able to generate sufficiently varied material, because each of these functions could be supplied with a different subset of the overall corpus by changing the descriptor constraints.
Traces of Function Outputs in Stitch/Strata
The Python-based scripting workflow consisted of generating sample phrases, auditioning them and retaining those that I anticipated would be compositionally useful. For me, this workflow felt more fluid than the “algorithm designer” mindset that was predominant prior to my shift to Python. My interaction with the computer at this point was largely centred around a back and forth between scripting with Python and then importing the sound files into REAPER for audition. This began as a pragmatic approach to listening to the sounds as small collections, but I found that while engaging with those materials, I was compelled to experiment with the sounds — to combine different outputs together, and to apply further audio processing and arrange the materials into larger musical structures. The piece evolved from this process and a higher-level formal structure emerged as a result of the dialogue between the various workflow aspects: scripting in Python, listening in REAPER and the ad-hoc arrangements I made with those materials as a result.
Stitch/Strata retained traces of the computer outputs, although many were additionally processed with playback-rate modifications and were rearranged or re-segmented manually in REAPER. The remainder of this section describes how some of them were incorporated into the final composition.
In one of the iterations generated by search_small, the query that was generated constrained the curation of samples to those with high spectral flatness, high centroid and low amplitude. This created a whispering texture which was used amongst several superimposed textural phrases at 3:03. The phrase itself can be heard in AUDIO 4.1.7.
jank created a number of glitch-like and robotic phrases. I composed with these more sparingly and wove them in between other phrases, at times emphasising the artificial qualities of the jank outputs for longer periods of time. This can be heard in AUDIO 4.1.8 which is located at 4:38 in the piece.
In addition to this, the outputs of jank were used to create constrained and tense textures that were prolonged. These functioned as formal points of stasis that were situated between active and gestural material throughout the latter half of the piece. This can be heard at 4:53, for example. AUDIO 4.1.9 shows this in isolation.
search_small phrases were interspersed with other materials and heavily edited from their original form to be presented more intermittently in the overall texture. AUDIO 4.1.10 captures this, which can be heard at 4:47 in the piece.
Outputs from accum_phrase were combined together to create unrelenting concatenations of vocal utterances. The repetition of short repeated phrases within the larger phrase itself can be heard. An example of this is in AUDIO 4.1.11. This was used as a long gesture that underpins the middle section of the piece at 3:15.
Even given the radical paradigm shift towards Python, I returned to using the dynamic descriptor-query approach, described in [4.1.2.3 Attempts to Have the Computer Generate Form]. This became a pivotal method for generating material that I then manually composed with. It was useful in creating contrasting gestural material in comparison to the more static and iterated nature of the Python scripts output. The first section of the piece is entirely composed of long dynamic queries spanning up to a minute. This created slowly evolving gestures where the change in query increases the spectral bandwidth and diversity of samples selected. This is demonstrated in AUDIO 4.1.12.
At 2:27, a dynamic query is used to create a rapidly changing texture encompassing highly noisy materials that reduce in amplitude over time. Refer to AUDIO 4.1.13.
A less linearly shaped query creates an oscillating gesture at 3:15. This is used to punctuate the beginning of a new section. Refer to AUDIO 4.1.14.
Reflecting on Human and Computer Agency in Stitch/Strata
The compositional process that took Stitch/Strata to its final version was entirely different from what I imagined it would be at the start of the project. The challenges incited by the initial goals, aims and self-imposed constraints — to create a piece “in the computer” — and the responses and solutions to those challenges, made me reflect on my initial aims and questions for this piece as well as for the PhD research more widely. I was certain from the experience of writing this piece that working entirely in the computer and relinquishing creative control to the degree that I initially tried to (particularly in the formal aspects of a work) was incompatible with my artistic goals and aesthetic preferences. However, this difficult process was formative and self-realisational. In many ways it outlined what aspects of composition I was willing to give away to the computer and at what stages I feel that I need to intervene with those processes. I arrived at a workflow where the balance of agency between me and the computer was more even, one which elicited a creative dialogue that allowed me to temper computer-generated outputs with my own intuitions and choices.
A main form of interaction that emerged between me and the computer was the process of auditioning outputs from the computer, particularly when I was using Python iteratively to generate versions of a process. This fostered an awareness of the samples within the wider corpus of previously unknown materials. While I had a broad idea about the nature of the sounds that I was working with, once the original vocal samples had been segmented there was no way that I could have listened to the 3,556 segments manually and operated on them meaningfully from that point without aid from the computer. The computer provided a structured exploration of those samples, grounded in filtering the larger corpus based on audio descriptors. This approach led me to thinking about groups of samples as blocks of material that could have highly specific and defined sonic properties, or as dynamic gestures shaped by their perceptual qualities.
Aspects of this workflow are evident in the high-level formal decisions that I made and that can be heard in the form of the final piece. 0:00 to 2:32 is built on the arrangement of dynamic queries, which are central to the formal direction and structure of this early section. From 2:32 to 3:56, perceptually tight concatenations of samples, derived through descriptor queries and organised by different Python-based procedures, are superimposed, with the superimpositions guided by my intuition and manual experimentation. 3:56 onwards is built on processes whereby I performed some manual segmentation and rearrangement of materials from the computer-generated outputs. These different approaches, concepts and organisational principles would not have emerged without the computer first offering initial materials for me to respond to.
This workflow, hybridising computer generation and my intuitive manipulation, was more fruitful than the initial one, where I assumed the role of “system designer” — and in which my agency is expressed through a layer of abstraction such as system parameters and constraints. Working only in that way did not engage me creatively, because I found it hard to conceive of a musical system that could encapsulate the ideas that I wanted to express, or one which was flexible enough to change throughout the creative process. Furthermore, I generally begin artistic projects from the point of a creative tabula rasa that is built on through experiencing and experimenting with sound materials. As such, I need to formulate the nature of the piece both artistically and conceptually through creative action. Intermittently testing ideas and deferring to the computer to guide that process facilitates this, rather than constantly having to work from an internal set of principles.
State and the Digital Audio Workstation
The transition from attempting to model specific musical structures, toward building smaller ones and working with them intuitively shifted my workflow from Max to a combination of REAPER and Python. Instead of focusing on having the computer formalise most if not all aspects of a work in a single “execution”, I moved toward a strategy in which the computer presented audio outputs as options or suggestions to me, which I could then modify, process, and change in place.
One significant difference in compositional workflow caused by this shift in technologies was the way I interacted with the computer’s outputs and reflected on them to develop the piece. Max does not inherently store or memorise anything to do with the state of a patch, such as changes to parameters or sounds that are generated while it runs. Those capabilities have to be built and implemented on a case-by-case basis which can be technically complicated, especially as the patch itself changes in response to creative developments or as new bits of code are introduced. This lack of “state” in my Max programming was something that I found difficult or impossible to address at the same time as thinking about creative problems. The movement to Python and REAPER helped to alleviate some of these issues, and it was only in hindsight that I realised how important managing the intermediate state of creative outputs is to my compositional process.
In particular, the ability to store, delete, colour-code, label, annotate and position audio files on a timeline fitted with my need to keep ideas in states of temporary completeness. By taking the outputs of the Python processes and situating them in a REAPER session, they became part of a “sketchbook” that could be modified, added to and grown as the piece did. This sketchbook approach allowed for flexibility in the fixity of the work as it developed. When I was not sure of the compositional usefulness of a computer-generated output, it could be kept temporarily in the periphery without having to discard it entirely. Ideas that I found particularly compelling were easily retained alongside information denoting their importance or projected use. The approach also allowed me to move between different creative mindsets fluidly, whether those mindsets were focused on sound-design, low-level manipulation of samples, or zooming out to observe the high-level formal aspects of a work. The DAW functioned as scaffolding which helped me to draw the computer into my practice when it was needed, rather than relying entirely on a system that I would have to design from the ground up myself.
Concluding Remarks
Stitch/Strata began with lofty compositional and creative aims that were challenged and eventually dismantled through the creative process. At the time, these changes to my creative practice and explorations of new ideas were as exciting as they were difficult to embrace. Reflecting on them now, there were many aspects of the workflow that emerged which became fundamental in my approach to composing Reconstruction Error and Interferences as well as in the development of FTIS, which leans on REAPER as an environment to explore computer generated-outputs aurally and to incorporate the contributions of the computer into my computer-aided practice.
The next project that is reflected on is Annealing Strategies. This work was another attempt to see how I could relinquish control to the computer, albeit with a different approach to the generation of sound and a deeper level of integration between the compositional material and the technical approach. In a number of ways this next piece was more successful, but the workflow that I built up through the creative process confirmed for me that relinquishing too much of my control and ability to intervene with the behaviour of the computer is not compatible with how I want to compose music in a computer-aided practice.